Основные вопросы
Перед тем как приступить к распознаванию речи нужно ответить на несколько вопросов:
1) Тип речевого сигнала(т.е. изолированные слова, непрерывная речь и т.д.)
2) Тип диктора( т.е. определенный(мужчина, женщина, ребенок), неопределенный)
3) Условия произнесения фраз(т.е. звукоизолированное помещение, машинный зал, общественное место)
4) Система передачи( т.е. высококачественный микрофон, узконаправленный микрофон, телефон)
5) Размер словаря(т.е. малый объем 20-80 слов, средний объем 80-100 слов, большой объем более 100 слов)
6) Формат произносимых фраз (т.е. ограниченный по длительности текст, свободный речевой формат)
7) Обучение.
Теперь мы можем ответить на эти вопросы относительно системы распознавания цифр.
1) Словарь малого объема ( цифры от 0 до 9).
2) Отсутствует ограничение на дикторов(на пол, возраст).
3) Условия на произношения: машинный зал, узконаправленный и высококачественный микрофон.
4) Обучение не предусмотрено.
5) Формат на входе - односословный с паузами между словами.
Такова была система распознавания речи в 1952. Современные же программисты преследуют следующие цели:
1) Непрерывная речь
2) Распознавание дикторов
3) Общественное место
4) Низкокачественный микрофон
5) Огромный размер словаря
6) И свободный речевой сигнал,
но как мы понимаем для нормальной работоспособнасти такой системы нам потребуется большое количество ресурсов. Таким образом появился новый вид обработки речевых сигналов. Если раньше речевые сигналы обрабатывались на месте, то теперь, для их обработки и преобразования, они посылаются на удаленный сервер, который затем присылает обработанный речевой сигнал обратно. Что разумеется требует больше времени, чем простое распознавание чисел со словарем из 10 слов, а также интернет.
Рассмотрим некоторые вопросы более внимательно. Представим, что поступает непрерывная речь. Как отделить одно слово от другого? Как понять где его начало, а где его конец?
Если мы находимся в звукоизолированном помещении или если есть шум, но незначительный, то проблемы нет. А если шум есть? И в какой-то момент времени он заглушает диктора. Например, в начале. Как найти в таком случае начало слова? Так же тяжело найти начало слова, если оно начинается со слабых фрикативных согласных, слабых глухих взрывных, носовых, вокализованных фрикативных и протяженных гласных в конце. Существует несколько алгоритмов для решения этой задачи, в основном они все используют энергию и переходы через 0.
Мы рассмотрим один из таких алгоритмов, алгоритм Рабинера и Самбура(Rabiner L.R. and Sambur M.R.).Этот алгоритм легко объяснить на примере. Возьмем произвольное слово, лучше произвольное словосочетание. В основу алгоритма входит число переходов через ноль и функция среднего значения в течение 10 мс(милисекунд).
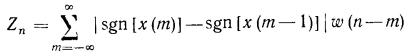
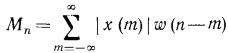
Обе функции вычисляются на всем интервале с частотой 100 Гц. 1 сек = 1000 мс
Предполагается, что первые 100 мс не содержат речевого сигнала, поэтому этот промежуток используется для определения статических характеристик шума, т.е. вычисления числа переходов через ноль и функции среднего значения. Далее, с учетом полученных результатов и максимального среднего значения на интервале вычисляются пороги для среднего числа переходов через ноль и энергии сигнала.
Затем, определяется фрагмент колебания, на котором траектория среднего значения превышает верхний порог. Предполагается, что начало и конец лежат вне этого фрагмента. Затем, двигаясь в обратном направлении, определяем момент, в котором траектория среднего значения оказалась меньше нижнего порога. Этот момент выбирается в качестве предполагаемого начала. Схожим образом находится и конец слова.
Тип речевого сигнала.
Непрерывной речью считается такая речь, в которой за одним словом следует сразу другое слово. Таким образом, получается, что фонема в конце одного слова влияет на первую фонему в начале следующего слова, что и препятствует распознаванию слов при непрерывной речи.В настоящий момент не существует алгоритма, способного распознавать слова при непрерывной речи, то есть используются лишь изолированные слова.
Тип диктора.
Хотя в каждом языке есть соответствующее ему количество фонем, у каждого человека свое соответствующее только ему произношение. Оно также индивидуально как и отпечатки пальцев. Однако, вне зависимости от индивидуальности речи, мы сможем отличить произношение взрослого человека от произношения ребенка, произношение женщины от произношения мужчины. Таким образом, системы распознавания речи можно разделить еще 2 способами: умеющие распознавать тип диктора и не умеющие этого. В основном распознавание типа диктора используется редко, т.к. на его смену пришла идентификация пользователя. Но рассмотрим более подробно пример распознавания мужского/женского типа произношения. Важным признаком для различия мужского и женского голоса является период основного тона, этот параметр характеризует частоту колебания голосовых связок при произнесении звонких звуков. Как правило, для мужчин характерны большие значения периода основного тона по сравнению с женскими.
Условия произнесения фраз.
Основные проблемы возникают при обработке условий произношения фраз. На данный момент ни одна, даже самая навороченная программа по распознанию речи не сможет в общественном месте отличить слово "Крюк" от слова "Трюк". Рассмотрим эту причину более подробно. Согласно Петербургской фонологической школе, в русском языке, как и в английском, 42 фонемы. Звук "К" относится к заднеязычным согласным, а звук "Т" относится к переднеязычным согласным. Как говорилось выше, определить начало слова, начинающегося с такого звука не составляет никаких проблем, тогда в чем же трудности? Вся проблема состоит в том, что в общественном месте основную часть шума составляет речь других людей. Если взять шум механического происхождения и речь, то речь имеет более хаотический порядок. Вследствии чего чужую речь наиболее тяжело убрать при обработке речи в общественных местах. Таким образом, чтобы система смогла распознать вашу речь, вам придется говорить громче всех остальных, т.е. в принципе кричать. Следовательно, вам придется переписывать весь словарь, заменяя произношение каждого слова, учитывая общественный шум, но если все так поступят, то это приведет к тому, с чего всё началось.
Система передачи речевого сигнала.
 В настоящий момент система передачи речевого сигнала является бичом всего речевого распознавания. Единственная
система передачи, которую используют все системы речевого распознавания, является высококачественный микрофон.
В настоящий момент система передачи речевого сигнала является бичом всего речевого распознавания. Единственная
система передачи, которую используют все системы речевого распознавания, является высококачественный микрофон.
Стоимость такого микрофона составлет 144,95 фунтов стерлингов, что приблизительно 6,5 тыс. рублей.
Размер словаря.
Что же касается словаря, то как мы убедились, они могут быть разных размеров. Рассмотрим их более подробно. Словари делятся на две группы. Первая группа словарей состоит из слова и его произношения. Такие словари необходимы для программы простого распознавания речи и её вывода на экран(или любое другое устройство вывода). Вторая группа словарей состоит из команд, к примеру "закрыть" или "свернуть" и их произношения. Часто программа со вторым типом словаря использует программу с первым типом. Чаще всего, для лучшего распознавания речи, некоторые словари имеют возможность настройки своей базы данных пользователем, т.е. убирать команды, изменять, добавлять слова. Так же словари разделяются по содержанию, некоторые из них содержат произношения целых слов, а некоторые произношение фонем. Отличие первого типа от второго заключается в следующем: хранение произношения целых слов занимает большой объем памяти и чаще всего используется для маленьких словарей, а хранение произношения лишь фонем занимает гораздо меньше места и не зависит от объема словарей. Так же для больших словарей используется тематика, слова разбиваются на темы и при определении слова определяется его принадлежность к определенной тематике.
Формат произносимых фраз.
Система распознавания речевого сигнала с ограниченным по длительности текстом обозначает, что сначала вся речь диктора будет записана и лишь потом, по истечении определенного количества времени, будет распознана. При свободном речевом сигнале речь распознается сразу при поступлении на распознающее устройство.
Что такое обучение?
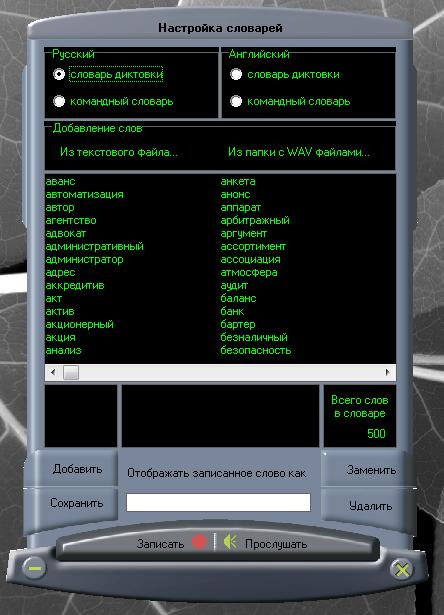 Обучение в распознавании речи это замена стандартного произношения слов в словаре.
Программы, имеющие в своих возможностях обучение зачастую являются не зависимыми от диктора. Обучение бывает двух типов. К первому типу относятся программы, в которых диктор сам определяет произношение каких
слов ему необходимо переписать. Такое обучение занимает от нескольких минут до часов, дней в зависимости от словарей и индивидуальности произношения. К
индивидуальностям произношения относятся заикание, дефект произношения некоторых букв и другие. Такое обучение является главной трудностью для диктора и
чаще всего после обучения первоначальное произношение удаляется. Ко второму типу относятся программы, в которых обучение проходит по мере их использования.
Если слово произнесенное диктором было распознано неправильно, то диктор может изменить произношение этого слова в тот же момент, в отличие от программ
первого типа, в которых словарь настраивается заранее.
Обучение в распознавании речи это замена стандартного произношения слов в словаре.
Программы, имеющие в своих возможностях обучение зачастую являются не зависимыми от диктора. Обучение бывает двух типов. К первому типу относятся программы, в которых диктор сам определяет произношение каких
слов ему необходимо переписать. Такое обучение занимает от нескольких минут до часов, дней в зависимости от словарей и индивидуальности произношения. К
индивидуальностям произношения относятся заикание, дефект произношения некоторых букв и другие. Такое обучение является главной трудностью для диктора и
чаще всего после обучения первоначальное произношение удаляется. Ко второму типу относятся программы, в которых обучение проходит по мере их использования.
Если слово произнесенное диктором было распознано неправильно, то диктор может изменить произношение этого слова в тот же момент, в отличие от программ
первого типа, в которых словарь настраивается заранее.
