
Алгоритм Кнута-Морриса-Пратта
Пусть даны некоторые строки 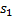 и
и 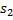 длиной соответственно
длиной соответственно 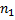 и
и 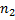 . Алгоритм Кнута-Морриса-Пратта позволяет найти все вхождения строки в строку .
. Алгоритм Кнута-Морриса-Пратта позволяет найти все вхождения строки в строку .
Для начала нужно найти символ 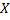 , которого нет ни в строке , ни в строке . Найдем теперь префикс-функцию
, которого нет ни в строке , ни в строке . Найдем теперь префикс-функцию 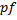 от строки
от строки 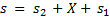 . Пройдем по массиву . Здесь возможны несколько случаев:
. Пройдем по массиву . Здесь возможны несколько случаев:
- Если
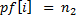 , то мы нашли вхождение строки .
, то мы нашли вхождение строки . - Если
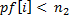 , то вхождения не обнаружено.
, то вхождения не обнаружено. - Если
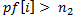 ,
то значит строки вида
,
то значит строки вида 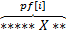 и
и 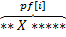 равны. То есть либо найден дубликат символа , что противоречит тому, как мы его выбирали, либо
сравнивался сам с собой. В этом случае префикс и суффикс имеют одинаковый вид
равны. То есть либо найден дубликат символа , что противоречит тому, как мы его выбирали, либо
сравнивался сам с собой. В этом случае префикс и суффикс имеют одинаковый вид 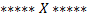 . То есть
. То есть 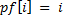 , что противоречит определению префикс-функции.
, что противоречит определению префикс-функции.
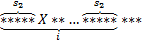
Таким образом, за один проход по массиву можно найти все вхождения искомой строки.
можно найти все вхождения искомой строки.Реализация алгоритма на языке С++:
std::string s = s2 + X + s1;
std::vector<int> pf(s.size() + 1, 0);
for (int i = 2; i < (int)pf.size(); i++) {
int prefLen = pf[i - 1];
while (true) {
if (s[i - 1] == s[prefLen]) {
pf[i] = prefLen + 1;
break;
} else if (prefLen == 0) {
break;
}
prefLen = pf[prefLen];
}
}
std::vector<int> positionsOfs2;
for (int i = 0; i < pf.size(); i++) {
if (pf[i] == s2.length()) {
positionsOfs2.push_back(i - 2 * s2.length() - 1);
}
}
Сложность алгоритма составляет 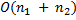 , т.к. алгоритм вычисления префикс-функции имеет сложность
, т.к. алгоритм вычисления префикс-функции имеет сложность 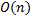 .
.
| |
Житов Александр, 2018 ФПМКТиФ ВоГУ |