
Суффиксный массив
Пусть 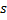 – это некоторая строка длины
– это некоторая строка длины 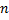 . Подстроку, которая начинается с
. Подстроку, которая начинается с 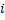 -го символа и заканчивается символом с индексом
-го символа и заканчивается символом с индексом 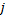 , будем обозначать
, будем обозначать 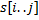 . Суффиксный массив для строки – это массив, состоящий из суффиксов
. Суффиксный массив для строки – это массив, состоящий из суффиксов  , отсортированных в лексикографическом порядке. Каждому суффиксу можно поставить в соответствие индекс его первого символа, поэтому в массиве достаточно хранить числа от
, отсортированных в лексикографическом порядке. Каждому суффиксу можно поставить в соответствие индекс его первого символа, поэтому в массиве достаточно хранить числа от 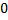 до
до 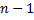 .
.
Рассмотрим пример. Пусть дана строка 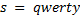 , тогда список отсортированных суффиксов, пронумерованных с нуля, для нее будет выглядеть так:
, тогда список отсортированных суффиксов, пронумерованных с нуля, для нее будет выглядеть так:
имеет вид 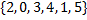 .
.Алгоритм построения
Сортировку суффиксов строки сведем к сортировке циклических сдвигов строки вида 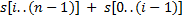 . Для этого добавим в конец строки некоторый символ, который будет меньше остальных символов строки. Далее подстрокой будем считать циклическую подстроку, то есть подстроку , которая при
. Для этого добавим в конец строки некоторый символ, который будет меньше остальных символов строки. Далее подстрокой будем считать циклическую подстроку, то есть подстроку , которая при 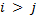 равна строке
равна строке 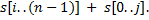
Сортировка происходит следующим образом: поэтапно сортируются подстроки длины 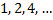 , пока их длина не станет больше длины исходной строки. На каждом шаге, кроме первого, сравнение строк происходит на основании данных, полученных на предыдущем шаге.
, пока их длина не станет больше длины исходной строки. На каждом шаге, кроме первого, сравнение строк происходит на основании данных, полученных на предыдущем шаге.
Для построения нам понадобятся два вспомогательных массива. Обозначим их 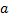 и
и 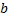 . Подстроки могут быть равны. На каждом шаге будем разбивать сортируемые подстроки на группы равных, причем номера группам будем присваивать в соответствии с лексикографическим порядком следования подстрок. Информация об этом будет храниться в массиве . В массиве будем хранить индексы первых символов подстрок. Эти индексы также будут идти в соответствии с лексикографическим порядком.
. Подстроки могут быть равны. На каждом шаге будем разбивать сортируемые подстроки на группы равных, причем номера группам будем присваивать в соответствии с лексикографическим порядком следования подстрок. Информация об этом будет храниться в массиве . В массиве будем хранить индексы первых символов подстрок. Эти индексы также будут идти в соответствии с лексикографическим порядком.
Рассмотрим шаг алгоритма с номером . Нам уже известны массивы и для предыдущего шага. Заметим, что любую подстроку длины 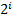 при
при 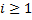 можно разбить на две подстроки длины
можно разбить на две подстроки длины 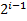 . А строки такой длины мы сравнивали на предыдущем шаге и информация об этом хранится в массиве . Пусть, например, требуется сравнить подстроки
. А строки такой длины мы сравнивали на предыдущем шаге и информация об этом хранится в массиве . Пусть, например, требуется сравнить подстроки 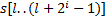 и
и 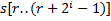 . Сравним сначала подстроки
. Сравним сначала подстроки 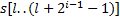 и
и 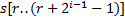 , то есть проверим равенство
, то есть проверим равенство 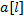 и
и 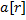 . Пусть
. Пусть 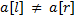 , тогда первая строка меньше второй, если
, тогда первая строка меньше второй, если 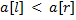 . Если же
. Если же 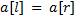 , то аналогично нужно сравнить
, то аналогично нужно сравнить 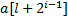 и
и 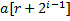 . Таким образом, мы можем построить новый массив за
. Таким образом, мы можем построить новый массив за 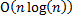 , так как сравнение подстрок выполняется за
, так как сравнение подстрок выполняется за 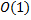 . Далее по нему можно найти новые значения массива . Всего будет примерно
. Далее по нему можно найти новые значения массива . Всего будет примерно 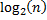 шагов, поэтому общая сложность составляет
шагов, поэтому общая сложность составляет 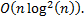
Реализация алгоритма на языке С++:
Задача о поиске подстроки
Приведем пример задачи, которая решается с помощью суффиксного массива. Пусть 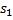 и
и 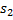 – это некоторые строки длины
– это некоторые строки длины 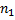 и
и 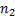 соответственно. Требуется найти вхождения в . Заметим, что , если она входит в , является префиксом некоторого суффикса строки .
Пусть мы имеем суффиксный массив для . Тогда можно искать с помощью двоичного поиска. Для проверки является ли строка префиксом нужно провести не более сравнений. Таким образом, если мы имеем уже вычисленный суффиксный массив, то сложность поиска произвольной строки равна
соответственно. Требуется найти вхождения в . Заметим, что , если она входит в , является префиксом некоторого суффикса строки .
Пусть мы имеем суффиксный массив для . Тогда можно искать с помощью двоичного поиска. Для проверки является ли строка префиксом нужно провести не более сравнений. Таким образом, если мы имеем уже вычисленный суффиксный массив, то сложность поиска произвольной строки равна 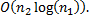
Заметим, что все суффиксы, для которых совпадает с их префиксом, будут идти подряд в суффиксном массиве. Следовательно, если требуется найти все вхождения в , то достаточно выполнить двоичный поиск дважды.
| |
Житов Александр, 2018 ФПМКТиФ ВоГУ |