Пример программы
Рассмотрим пример задачи, которая очень хорошо параллелится. Это может быть перемножение матриц или сложение векторов (об этом можно прочитать почти во всех статьях про CUDA). А мы посчитаем интеграл 4/(1+x*x) на отрезке [0,1] методом прямоугольников. Как нам подсказывают, он равен Пи. Вот так может выглядеть простейший код на С:
Теперь попробуем сделать то же самое, только на видеокарте.
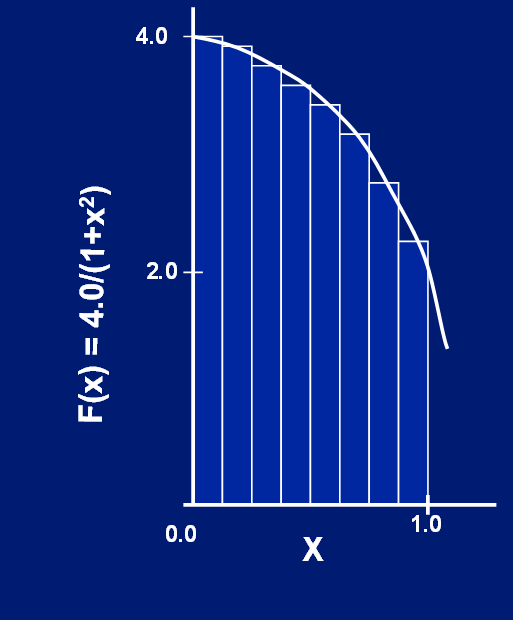
Интегрирование по формуле прямоугольников: каждая полоска соответствует "шагу" фиксированной ширины. Высота каждой полоски равна значению подынтегральной функции. Если соединить вместе все полоски, можно приблизительно вычислить площадь под кривой, то есть значение интеграла. Создадим массив длиной numSteps и в каждый элемент этого массива запишем площадь соответствующего прямоугольника. Мы можем вычислить площадь одного прямоугольника независимо от других. Вот здесь нам и понадобится параллелизм. За вычисление площади каждого прямоугольника будет отвечать один поток. Далее нам остается только просуммировать элементы массива и получить значение интеграла.
cudaMalloc() - аналог сишной malloc() и она занимается тем, что выделяет область в глобальной памяти. Размер блока (blockSize) лучше всего делать равным 2^n - 4 , а структуры лучше выравнивать по границе в 16 байт (чтобы избежать так называемых конфликтов банков памяти).
Далее подготовим данные - занесем значения в массив.
И передадим этот массив в память видеокарты.
Основные вычисления:
Спецификатор __global__ показывает, что функция относится к ядру - её вызовет CPU, а выполнит GPU.
Так же есть __device__ функция, которая выполнится на GPU и вызвать её можно только с GPU. Можно еще писать (а можно и не писать) спецификатор __host__ - функция вызывается CPU и выполняется на CPU, т.е. это - обычная функция.
__global__ и __device__ функции не могут быть рекурсивными и должны содержать постоянное число аргументов.
Т.к. функции __global__ и __device__ выполняются на GPU, то запустить их под обычным отладчиком и получить их адреса не получится. У NVIDIA есть специальные средства для этого, можно посмотреть на официальном сайте.
Каждый вызов __global__ функции должен соответсвовать спецификации вызова. Спецификация определяет размерность сетки и блоков, которые будут использоваться для выполнения этой функции на устройстве. Вызов должен соответсвовать форме:
func<<< Dg, Db, Ns, S >>>(arguments)
Dg имеет тип dim3 и определяет размерность сетки, так Dg.x * Dg.y равно числу блоков. Тип dim3 трехмерный, но координата Dg.z обычно не используется.
Db тоже имеет тип dim3 и означает размерность и размер каждого блока. Значение Db.x * Db.y * Db.z равно числу потоков в блоке.
Ns имеет тип size_t и определяет число байтов в shared памяти, которая динамически размещается для каждого блока в дополнение к статической памяти. Ns необязательный параметр и по умолчанию равен 0.
Параметр S типа cudaStream_t , определяющий дочерние потоки. S также необязателен с параметром по умолчанию, равным нулю.
Встроенные переменные:
blockIdx - номер блока внутри сетки
threadIdx - номер потока внутри блока
blockDim - число потоков в блоке
blockIdx и blockDim- трехмерны и содержат поля x,y,z, а сама сетка двумерна.
Т.к. массивы у нас одномерные, используется только координата x.
После того, как провели вычисления, нужно передать данные обратно на хост :
cudaMemcpy(a_h, a_d, size, cudaMemcpyDeviceToHost).
cudaMemcpyDeviceToHost - копирование с устройства на хост, cudaMemcpyHostToDevice - соответственно обратно.
Еще несколько действий и выводим результат : 3,141592.
Полный текст программы можно посмотреть тут, откомпилированную версию программы здесь. Так же доступны для скачивания программа для устройств CUDA и её аналог в режиме эмуляции.